Have you ever wondered how it happens that search results are delivered to a user so quickly? Even when there is a big dataset behind the search engine API, searched items are usually delivered in milliseconds. How so?
This article is a part of the Text Search series by Łukasz Kuczyński
Behold the power of index. An index is an entity living in the world of databases to speed up your work. The same is true in the case of Elasticsearch – the main product in the Elastic stack. There is an index that makes search effective. But how did it appear there? To answer, we need to go back in time to the year 2000. It was the time when Mr. Doug Cutting realized he needed to build a search engine. And to make it clear: Lucene was not his first 🙂 You can see an interesting timeline on Elastic “Celebrating Lucene” doc, which explains what a long way it has been from Mr. Doug’s first invention up to now. Currently, more than 20 years after its beginnings, Lucene is still the backbone of Elasticsearch. However, Lucene is an open-source project. You can make your hands dirty and help in its development.
Lucene index
The success behind Lucene lies in the way it places data chunks in order. In any data-related solution, it is crucial to think about the data engine in advance in order to choose the right tool for the job. Lucene was created with text search in mind. To make text search efficient, Lucene in general stores data in documents and fields. What do these objects represent?
Document
A document is a collection of fields. Fields have names and values. If you have an IT background, you may think of it as a dictionary with keys and values. When it comes to textual data, Lucene has two main approaches – storing it as the whole text or a tokenized sentence. Tokens are parts of the text that were selected and extracted from it.
For example, when having these 2 texts we will choose 2 different strategies.
```json{
“team”: “Manchester United”,
“description”: “after a wonderful game Manchester United defeated FC Liverpool”
}
“`
You will agree that the 1st field does not need to be analyzed or tokenized – it’s just the name of a football club. We should simply store it in our database. However, the second field `description` should be treated differently. It is a sentence, and there are some “stop words” (grammar elements not affecting the meaning), so we should analyze it and store only significant words (tokens) in a selectable form.
Inverted index
To enable quick searching, Lucene places everything in an inverted index by default. To visualize this, check the following set of 3 documents and the inverted index that was created as the result:
Id: 1
Text: Description after a wonderful game Manchester United defeated FC Liverpool
Id: 2
Manchester City players once again showed a great attitude in the game against Everton.
Id: 3
Text: In the game of Arsenal and Everton there was a draw, so Arsenal’s players were disappointed
Inverted index:
…
...
Manchester: 1,2
Arsenal: 3
...
Such an index is the way for Elasticsearch to satisfy quick querying of textual information. In this index, the engine puts document id with tokens being keys. It enables you to find documents based on tokens in milliseconds.
A little about SOLR
SOLR is a web tool presenting Lucene tools as a web service. For several years, it was the only choice for developers to use. What are the key differences between this solution and Elasticsearch? You may find the following table useful:
| Solr | Elasticsearch | |
| maturity | mature | younger |
| scalability | manual | built-in |
| Documentation and community | not extensive | full and extensive, big community |
| cloud | manual installation | available on major clouds, offered as SaaS |
| security | external providers | built-in |
There is no clear choice that says: You should favor SOLR over Elasticsearch or otherwise. However, taking into account the community and documentation, Elasticsearch seems to be a safer choice. With the advancement of other search solutions, Elastic company set it as a goal to also provide AppService and Workplace Search, which are great to automate some ideas for product marketing and internal knowledge management.
Elasticsearch – get started
Before you start working with Elasticsearch, you need to have a cluster running somewhere to be able to issue queries and aggregate your data. It can be likened to a Database server which has to be up and running before you can use SQL against it.
There are several options to run Elasticsearch. You can do it self-hosted, run it on a virtual machine of your choice, or use the SAAS option which has everything set up for you. The last option is the easiest, and we recommend aiming for it if you are not sure if this is the tool for you. The recommended SAAS is using this form [official elastic site](elastic. co). Let’s not forget about other solutions like `bonsai.io` or cloud-dedicated implementations like OpenSearch ( Elasticsearch fork).
In the next article, you will learn how to use a variety of tools that Elastic brings to the table. However, in this section, we will introduce you to Kibana, which is a dedicated user interface for Elasticsearch. You could work without it, but it makes life so much easier.
Elasticsearch enables you to work with your data. However, if you are at the beginning of your journey you can add sample data with just one click in Kibana.
Index, documents
The basic words you have to learn about Elasticsearch are:
- index
- document
An index is a collection of documents, usually having a similar structure. For instance, we would like to collect news about football games in the first index and bios of players and trainers in the second. However, it is not enforced as we can think of Elasticsearch as a NoSQL database that does not enforce a schema. If you installed an eCommerce orders sample dataset, you should be able to issue a simple GET request against the newly created index. The index we created from sample data is `kibana_sample_data_ecommerce`. Elasticsearch provides a REST framework for Lucene indices; hence, we can query this data. If you are using Kibana, it’s convenient to use Dev Tools and send your queries from there.
```
GET /kibana_sample_data_ecommerce/_search
```
When queried like that, the Elasticsearch node responds with a collection of documents. These are the documents that were indexed (INSERTed so to speak) when we added test data into our collection. Now we can get them. As you can see, there are several JSON documents there. There is a mapping that describes types but it was not necessary to create it beforehand. We just see something like this, take a look into our collection dev tools window:

Another way of browsing documents is using built-in dashboards, f.e. Kibana. In this tool, you can browse data using KQL or Lucene query. The last one is the visible proof that we are working with a Lucene-based tool here.
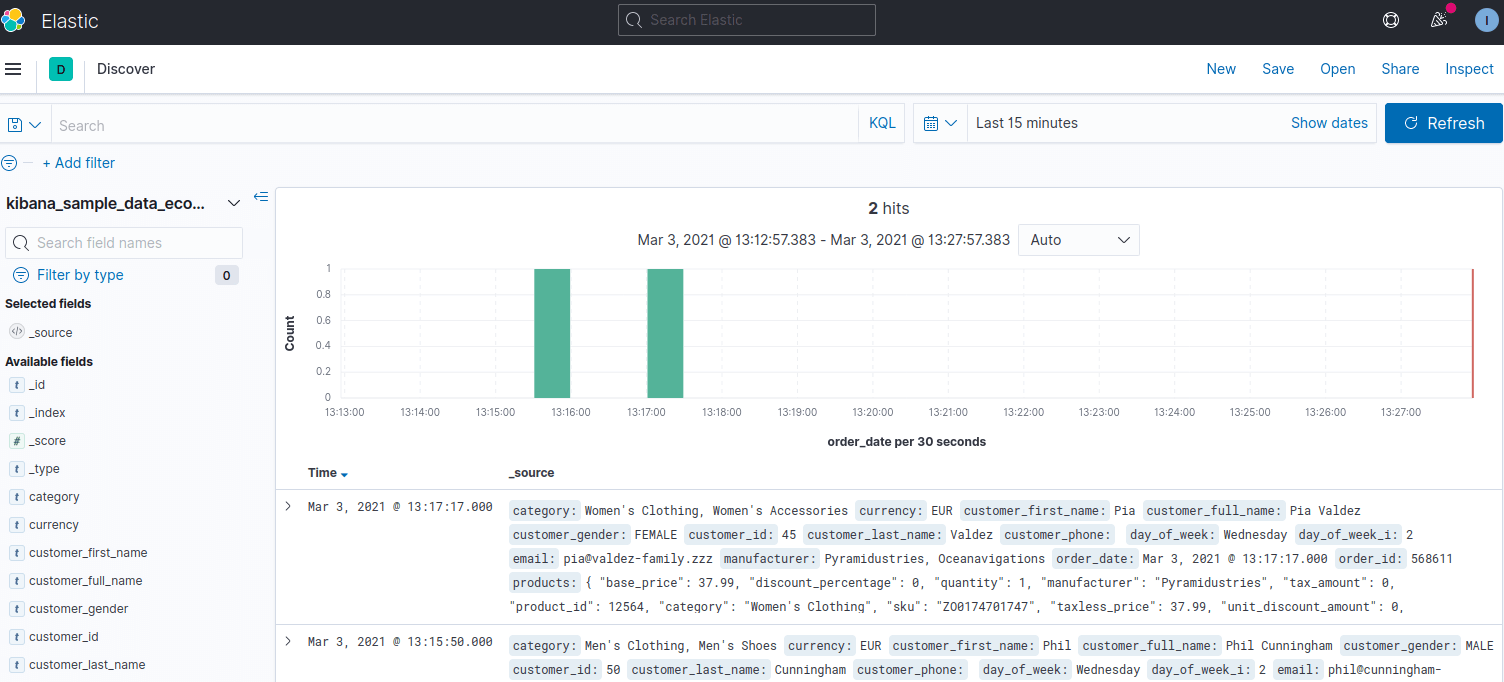
The very fact that we can analyze histograms proves that we can use grouping and aggregations. As a database user, you may find using `GROUP BY` queries a convenient way to get data summaries.
Aggregations
Elasticsearch provides several aggregation functionalities that you can test out of the box using only REST API. If you want to have a general feeling of how many documents are there, issue a `_count` command with REST call, like that:
```
GET kibana_sample_data_ecommerce/_count
```
In response, you will receive a count together with some advanced statistics.
```json
{
"count" : 4675,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}
```
When working with time-related data, you often need to aggregate the data by using the index of datetime values. This is the moment where `date_histogram` aggregation comes in handy. To get the weekly counts of orders in the sample ecommerce dataset, we will need to send the following GET query:
```
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"2": {
"date_histogram": {
"field": "order_date",
"calendar_interval": "1w",
"min_doc_count": 1
}
}
}
}
```
The results are JSON containing weekly counts. Results may be similar to the following:

This aggregation is just a sample of what happens when you browse data using the Discover option in Kibana.
Wrapping it up, to start playing with Elasticsearch you don’t need to set up a whole machine yourself. You can start with easy elastic. co and index documents in a blink of an eye. With default tools like Kibana, it’s easy to browse documents and leverage the power of full-text search.
Outro
Elasticsearch is a solution that fits nicely with text analysis tasks. We could see what its engine is and what the main nouns used in Lucene vocabulary are: document and inverted index. Several main players are using Lucene as its Backend, we mentioned SOLR and Elasticsearch. There was also a brief introduction to performing basic operations such as indexing, searching, and aggregations. In the next episode, we will take a sneak peek at how Elasticsearch fits into the ecosystem developed by the Elastic community.

Managing Director
& Co-Founder of Exlabs