Concurrent access control is a critical aspect of web application security.
It ensures that multiple users accessing the same resource or data do so in a controlled and orderly manner, without interfering with each other’s actions. This is especially important in web applications that involve sensitive data or financial transactions, as concurrent access can lead to data corruption. Even though this aspect is very important, developers still tend to forget about securing their applications, and introduced problems can be hard to detect in the early stages of the project, especially when the traffic is not very high.
Problem
Let’s imagine that we have a blogging platform where users can upvote posts they like. Here is what that flow looks like:

A user can see the current upvotes count, upvote the post and successfully increment the counter. But what can happen when at the same time two users enter the page and at the exactly same time decide to upvote the same post? When there’s no prevention, the following scenario can happen:
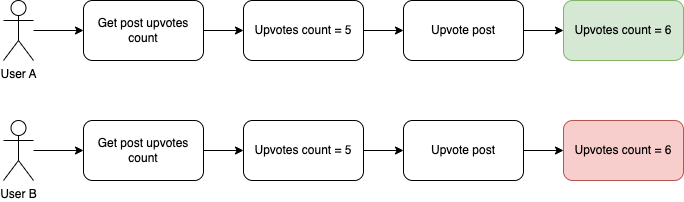
And here we have a result that definitely was not expected.
Solution
In the database world, there are two approaches to deal with such problems:
- Pessimistic concurrency control – in this approach the resource is exclusively locked and only the thread that placed the lock is capable of making changes to the resource. This approach is not supported by Elasticsearch.
- Optimistic concurrency control – the approach used by Elasticsearch, where we can detect that there were changes applied to the resource between reading and writing. When trying to update the already modified record, the update operation is going to fail.
The most common approach to achieve optimistic locking is to make use of version or timestamp attributes. When one thread updates the resource, it automatically updates the version or timestamp. Then, when another thread would try also to update the same resource and it detects that the version or timestamp attribute differs, the update is going to fail.
How do we achieve this in Elasticsearch? The solution here is very similar, but instead of version and timestamp fields, we make use of:
- Primary term – it’s essentially the counter that increments every time the primary shard is selected in the replication group.
- Sequence number – is a counter that is incremented with every write operation.
The usage of these two parameters was introduced as Elasticsearch is a distributed and asynchronous platform and bad things can happen – there is a risk that the primary shard fails before successfully finishing replication and then we would achieve a situation when some operations were not replicated in all the replica shards!
So, how can we make use of those two attributes? Let’s prepare sample data to store in our index. Using a client of choice, let’s create the following blog post:
POST /posts/_doc/2
{
"content": "Hello, World!",
"author": "John Doe",
"upvotes": 5
}
It should return a response that looks similarly to this:
{
"_index": "posts",
"_id": "2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 5,
"_primary_term": 1
}We can see that it’s returning us the mentioned attributes – _primary_term and _seq_no . This is a response to the creation action. When we query for this post it should return us the same values. Let’s find out:
GET /posts/_doc/2
Response:
{
"_index": "posts",
"_id": "2",
"_version": 1,
"_seq_no": 5,
"_primary_term": 1,
"found": true,
"_source": {
"content": "Hello, World!",
"author": "John Doe",
"upvotes": 5
}
}Everything is fine – _primary_term and _seq_no haven’t changed. But what is going to happen when we update the post?
Request:
PUT /posts/_doc/2
{
"content": "Hello, World!",
"author": "John Doe",
"upvotes": 6
}
Response:
{
"_index": "posts",
"_id": "2",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 6,
"_primary_term": 1
}As we can see, after the update, the _seq_no incremented. But this update wasn’t performed in a safe way. In order to achieve optimistic locking, we need to add two parameters to the update action:
- if_seq_no
- if_primary_term
And then the request looks as follows:
PUT /posts/_doc/2?if_seq_no=6&if_primary_term=1
{
"content": "Hello, World!",
"author": "John Doe",
"upvotes": 7
}
This should give us the following response:
{
"_index": "posts",
"_id": "2",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 7,
"_primary_term": 1
}Which is just an expected successful response – _seq_no attribute was once again incremented. But what’s going to happen when we perform exactly the same request without changing the parameters? When performing that request, we are asking Elasticsearch to update the record with the provided ID only when the _seq_no and _primary_term are the same as those that we provided in the URL. So let’s find out what’s going to happen when these values don’t match:
PUT /posts/_doc/2?if_seq_no=6&if_primary_term=1
{
"content": "Hello, World!",
"author": "John Doe",
"upvotes": 7
}
While performing the same request as previously, this is the response that we get:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[2]: version conflict, required seqNo [6], primary term [1]. current document has seqNo [7] and primary term [1]",
"index_uuid": "OC-j1KACTbmrb88_bXjZyA",
"shard": "0",
"index": "posts"
}
],
"type": "version_conflict_engine_exception",
"reason": "[2]: version conflict, required seqNo [6], primary term [1]. current document has seqNo [7] and primary term [1]",
"index_uuid": "OC-j1KACTbmrb88_bXjZyA",
"shard": "0",
"index": "posts"
},
"status": 409We’re getting a 409 status response along with the error description that states the sequence numbers don’t match.
So what should we do now with such errors? It’s up to the developers’ decision – the post can be either read and updated one more time or some kind of error can be returned to the end user, informing that the update could not be performed. Anyway, it needs to be resolved on
the application level.
Summary
In this post we learned how we can easily make use of the Elasticsearch mechanism in order to achieve optimistic concurrency control. Such an approach makes the state of our applications much safer without impacting the performance.