CQRS - another "buzzword"
or game changer?
Did You have a situation when you started the project from scratch, where at the beginning most of the tasks took you a moment, but as the project developed, was it getting harder and harded to add a new feature without interfering with the existing code? Yes, I also had this problem until I learned the CQRS pattern.
But what is CQRS anyway?

Before we get to CQRS, it’s worth learning the concept that CQRS evolved from. The CQS (Command Query Separation) concept, presented by Bertrand Mayer in 1986, says that each function in the system should be classified into one of two groups:
– commands – functions that mutate the application state but do not return anything;
– queries – functions that do not mutate the state and return specific data.
Quote taken from Mayers book “Eiffel: a language for software engineering” presents well the CQS concept in one sentence “Asking a question should not change the answer.”
Moving on to the details, the code we write using CQS should not contain methods that do one of two things depending on the situation, for example, when we want to fetch a product from our application by attributes, the function should not create such a product if it does not exist.
| function getOrCreateProduct(data: ProductData) { | |
| let existingProduct = productRepository.findByAttributes(data); | |
| if (!existingProduct) { | |
| existingProduct= productRepository.save(data); | |
| } | |
| return existingProduct; | |
| } |
The condition contained in the function clearly indicates to us the division between the mutation, i.e. our command and query, such a function should be broken down into two separate functions, respectively, to save and read our product.
When object-oriented languages became more popular, Greg Young and Udi Dahan proposed the CQRS pattern – Command Query Responsibility Segregation. This pattern is very simple, it really extends CQS with object-oriented approach, in other words we do not use the division only at the function level but at the whole system level.
First battle – CQRS and code
In the first situation, let’s look at how CQRS relates to the code itself. We usually distinguish four classes such as Command, Command Handler, Query and Query Handler.
Command is a class that defines a command for us by the type of command, after which the command will be identified and the data needed to process the command. The command can be identified by an instance of the class or by an internal variable that describes the command using a string, e.g.
| abstract class Command<T> { | |
| constructor(public readonly type: string, public readonly payload: T) {} | |
| } |
And the implementation of a specific command can look like this:
| interface RegisterCustomerPayload { | |
| email: string; | |
| password: string; | |
| name: string; | |
| } | |
| export const REGISTER_CUSTOMER_COMMAND_TYPE = “customer/register”; | |
| class RegisterCustomerCommand extends Command< | |
| RegisterCustomerPayload | |
| > { | |
| constructor(payload: RegisterCustomerPayload) { | |
| super(REGISTER_CUSTOMER_COMMAND_TYPE,payload); | |
| } | |
| } |
As you have probably already guessed the command itself with the type and data will not help us, we have to handle this command and here Command Handler comes to our aid:
| abstract class CommandHandler<T extends Command<unknown>> { | |
| constructor(public readonly type: string) {} | |
| public abstract async execute(command: T); | |
| } |
Returning to our example with customer registration, the implementation of command support might look like this:
| interface Dependencies { | |
| customerRepository: CustomerRepository; | |
| } | |
| class RegisterCustomerCommandHandler extends CommandHandler< | |
| RegisterCustomerCommand | |
| > { | |
| constructor(private readonly dependencies: Dependencies) { | |
| super(REGISTER_CUSTOMER_COMMAND_TYPE); | |
| } | |
| public async execute({ payload }: RegisterCustomerCommand) { | |
| const { customerRepository } = this.dependencies; | |
| const { email } = payload; | |
| const existingUser = await customerRepository.findByEmail(email); | |
| if (existingUser) { | |
| throw new Error(`User with email: “${email}” already exist.`); | |
| } | |
| await customerRepository.insert(payload); | |
| } | |
| } |
It is worth noting that the constructor of our class can be used as an aggregate of dependencies needed to process our command, i.e. using dependency injection we can inject any interface implementation that interests us.
As we mentioned earlier, commands should not return anything, of course in more complex cases it is quite difficult to achieve because we usually need some data after processing the command. It is a good practice to return transaction-related data rather than the lower abstraction layer, e.g. domain level. So nothing prevents you from returning the entity id of the customer, but you don’t want to return the entire entity.
And the question “why?” May appear. Usually, our commands are run by a higher abstraction layer, which should have as little information as possible about the lower abstraction layers, so when we return a primitive data type, e.g. string, we avoid penetration of abstraction layers, in other words, we do not force the upper layer to inform about our domain entities, e.g. Customer.
When it comes to queries, the implementation looks quite similar, we have Query, which again has the type and data needed to process the query, and we have Query Handler, which supports the query.
Queries should return data as soon as possible, really there is the least logic here and we talk directly with the persistence layer, it can be pure SQL, query builder or client e.g. for Elasticsearch. Here is also a good place to map data to DTO. But really, we should directly persuade the data to views, e.g. in the form of a separate table.
| interface GetUserEnrolledDecksQueryHandlerDependencies { | |
| enrolledDeckRepository: EnrolledDeckRepository; | |
| deckElasticView: ElasticView<Deck>; | |
| storageClient: StorageClient; | |
| } | |
| export class GetUserEnrolledDecksQueryHandler extends QueryHandler< | |
| GetUserEnrolledDecks, | |
| GetUserEnrolledDecksQueryResult | |
| > { | |
| constructor( | |
| private readonly dependencies: GetUserEnrolledDecksQueryHandlerDependencies, | |
| ) { | |
| super(GET_USER_ENROLLED_DECKS_QUERY_TYPE); | |
| } | |
| public async execute({ payload: { userId } }: GetUserEnrolledDecks) { | |
| const { | |
| enrolledDeckRepository, | |
| deckElasticView, | |
| storageClient, | |
| } = this.dependencies; | |
| const enrolledDecks = await enrolledDeckRepository.getAllByUser(userId); | |
| const { items } = await deckElasticView.findMany({ | |
| ids: enrolledDecks.map(enrolledDeck => enrolledDeck.getDeckId()), | |
| }); | |
| return new GetUserEnrolledDecksQueryResult( | |
| items.map(item => ({ | |
| …item, | |
| imgUrl: item.imgUrl | |
| ? storageClient.getPublicUrlResolver(item.imgUrl) | |
| : ”, | |
| })), | |
| ); | |
| } | |
| } |
In the example above, the final data is extracted with the help of the client for Elasticsearch, it can be seen that the implementation is focused only on the extraction and mapping of data, which will then be returned by the API.
One tool to rule them all
We already know what commands and queries are, we also know how to handle them. However, the question may appear how to run such commands and queries from a higher abstraction layer? Is there any generic way? We can build a certain tool that will store all Command Handlers in our application, e.g. using a container and will provide a method that accepts any command, looks for the appropriate Command Handler and execute our command, such a tool is called Command Bus and we can prepare such a tool for queries – Query Bus.
| class CommandBus { | |
| constructor(private readonly handlers: CommandHandler<any>[]) {} | |
| public async execute(command: Command<unknown>) { | |
| const handler = this.handlers.find( | |
| (existingHandler) => existingHandler.type === command.type | |
| ); | |
| if (!handler) { | |
| throw new Error(`Handler for command: ${command.type} does not exist.`); | |
| } | |
| return handler.execute(command); | |
| } | |
| } |
Then to run any command available in our application just call the execute method from the CommandBus class.
| const registerCustomerAction = ( | |
| payload: RegisterCustomerPayload, | |
| context: ApplicationContext | |
| ) => context.commandBus.execute(new RegisterCustomerCommand(payload)); |
As you can see, thanks to a simple tool we can easily separate the call of a command without knowing how such a command will be handled in the lower abstraction layer.
The battle continues – problem of data persistence
Can the CQRS approach only be used in business logic? Of course not, we can go lower and apply CQRS to the persistence of our data. You may have encountered a situation where the client application required displaying information from several tables in one place. Of course, in this case, we can write an endpoint that aggregates data from several tables, whether using repositories, ORM or another tool, sticks the data and finally returns it in one form. As you can see, this is quite a complicated procedure, a lot is happening here, the complexity is increasing and in addition in most applications we read data more often than we mutate it, thus such an endpoint can be run very often, which can negatively affect the performance of our website. How can we remedy this?
Let’s meet the “Read Model”, which is also known as “Projection”. It is nothing but a separate entity, often a new table in our database, which exists next to existing tables that persuade information about our business, these models are called “Write Model”. The read model can also exist in a separate database, often they are NoSQL databases like MongoDB or Elasticsearch.
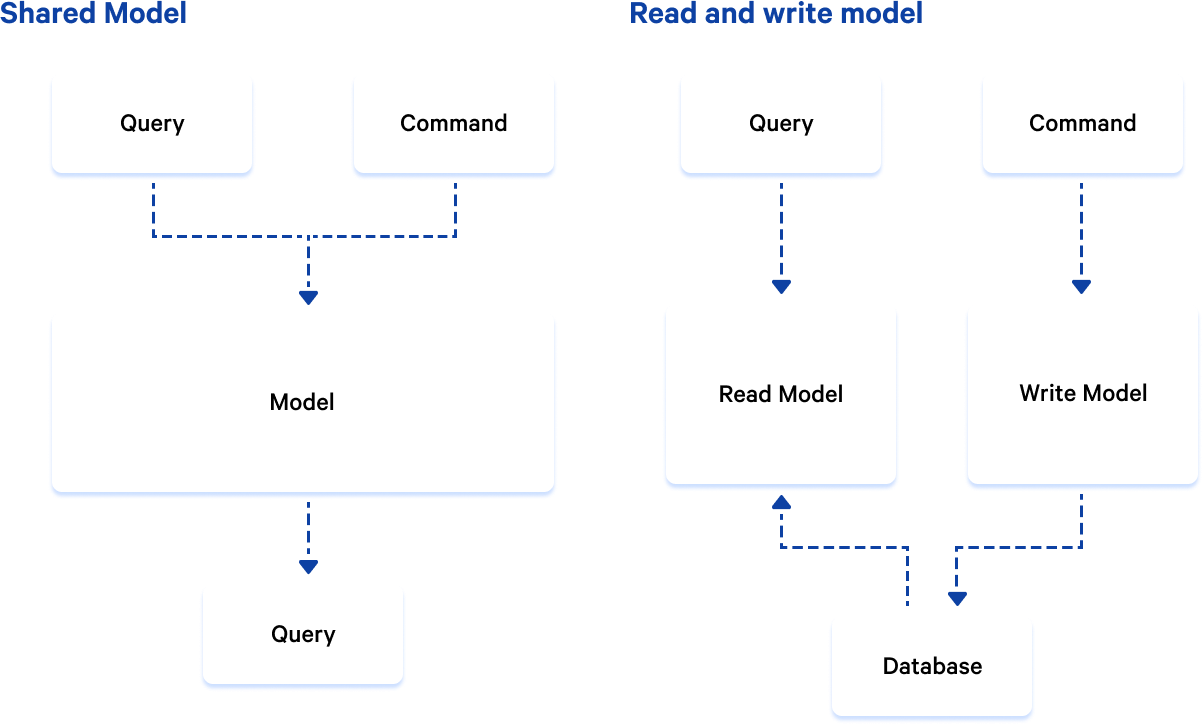
As you can see in the picture above, the query and the command have their own separate models for reading and writing, where the command saves data to the appropriate tables that persuade our business, in addition, an event is usually run or the commands are simply also persuaded data as a read model.
Final battle – API
We know how to use CQRS directly in the code, we also know that CQRS can be used in the layer of persistence. Is there anything else? CQRS can also be used in the API layer, but this is a more arbitrary issue. For example, GraphQL divided the queries into Mutation and Queries, technically nothing prevents Query from mutating the state of our application, of course this is not a good practice.
| export const resolvers = { | |
| Mutation: { | |
| addCardToDeck, | |
| removeCardFromDeck, | |
| }, | |
| Query: { | |
| getCardsForDeck, | |
| }, | |
| }; |
What is good is a clear division of our API – regardless of whether it is HTTP REST, GRPC, WebSockets or other solution – to just queries and commands, it gives us so much that the consumer of our API knows in advance whether it mutates the state of the application or just reads data. In addition, we can impose a time window for commands, for example 100 requests mutating the state of the application within 5 minutes and more for query requests because they are less demanding for our system.
Legacy system and CQRS
There may be a question whether it is worth using CQRS in legacy systems and whether it can be at all or maybe the CQRS pattern is only for new systems?
Of course, as you have noticed, CQRS is quite simple to implement and can be easily added to an existing system. And what will it give us? Above all, performance and scalability. If you have queries in your system that require contact with several tables, you can create a Read Model, in addition, when we use an additional abstraction layer, e.g. ORM, you can easily replace this layer with a simple SQL query to table which is responsible for the view.
Most systems read data more often than mutate it, if we move the tables responsible for projections to a separate database, where we can additionally choose which type of database will work best in our case, e.g. graph database, elasticsearch or NoSQL.
Whatever we choose, it will be a separate database that can be easily scaled without worrying about the rest of our system.
The second aspect when adding CQRS to an existing system can be a frequently changing business. It is easier to manage the class responsible for calling business logic (Command Handler) than to look for places where change can affect other parts of our system.
When we should consider using CQRS?
When we hear about CQRS, it often appears with the concept of Event Sourcing or Domain Driven Design in general. We can use CQRS separately, the question is whether there is always sense. Of course, when we write a typical CRUD, which I understand as adding an additional API layer for communication with persistence, there is no sense.
In this case, CQRS will hurt us more than it will help. However, when our application has a complex business domain, which often changes, where there are a lot of specific queries, the use of CQRS can make it much easier for us either by breaking down read and write persistence or separating business logic in the form of commands.
In addition, it is worth bearing in mind that CQRS can easily be expanded with other tools such as Event Sourcing if there is such a need. Therefore, CQRS is a very good introduction to improving the system architecture.
Need our help?
Let us know more about your needs.

Managing Director
& Co-Founder of Exlabs